
Tech Trend Translator: The PM Brief
2026/05/19 21:40:49@NeoDrop Official
AI video's Figma moment
Google unveiled Gemini Omni at I/O 2026 — a unified model that generates text, images, and video from a single interface with conversational editing. The competitive question in AI video has shifted from "which model makes the best first clip" to "which workflow lets a team iterate fastest." Two videos already consume 86% of the daily AI Pro quota, no API is confirmed yet, and a new Tsinghua benchmark shows logical reasoning remains the hardest unsolved problem for every current video model.
This is a catch-up brief covering May 15–19 — a four-day window with more signal than a typical day. One trend dominated: Google's Gemini Omni, unveiled at I/O this morning. Here's what changed, what the constraints actually are, and where to place your bets.
One model for text, image, and video
Gemini Omni is Google's unified multimodal generation model, demoed by Sundar Pichai at Google I/O 2026 on May 19.1 The pitch: one model, one interface, every creative output format.
The keynote showed style transfer — realistic footage rerendered in glitch, then pencil-sketch — while preserving character identity and motion across the full sequence.2 Science explainer videos (photosynthesis, a V8 engine, wave mechanics) ran up to two minutes with physics accuracy intact — one demo correctly depicted blue light scattering roughly 10x more than red, the λ⁴ dependence for Rayleigh scattering.3
The leaked Gemini app UI description said it plainly: "Meet our new video generation model. Remix your videos, edit directly in chat, try a template, and more."2
That last phrase — edit directly in chat — is the part that matters. Not because of what the model can generate, but because of how you interact with it once it does.
Omni is available on Google AI Pro ($19.99/month) — no Ultra tier ($249.99/month) required.4
The actual problem it solves
The current AI creative stack for most product teams is three tools running in parallel: image generation (Midjourney or Flux), video synthesis (Runway or Kling), audio/voiceover (ElevenLabs or a separate model). Each handoff costs iteration cycles — you adjust the image prompt, re-export, re-upload to the video tool, re-sync the voiceover. A single "make the background warmer" note means touching three systems.
When Google says "edit directly in chat," the claim is that you skip those handoffs entirely. A conversational instruction routes directly to the model, which holds context about the prior generation. PixVerse, in its competitive analysis of Omni, framed the shift clearly: "If Google can make video changes through ordinary chat instructions, the competitive question shifts from 'which model makes the prettiest first clip?' to 'which workflow lets a creator fix the clip fastest?'"5
The competitive context also shifted in Google's favor. OpenAI shut down Sora in March 2026. Google publicly responded by committing to video generation — "video's here to stay."2 Runway (Gen-4), ByteDance (Seedance 2.0), Kuaishou (Kling 3.0), and PixVerse V6 remain the other primary competitors — but none of them have Google's ecosystem surface area across Android, Chrome, Workspace, and, soon, Android XR glasses.6
The constraints are real
Before you put Gemini Omni on a product roadmap, three friction points need honest handling.
Usage economics are brutal at current quotas. A pre-launch Google AI Pro user generated two Omni videos and consumed 86% of their daily usage limit.2 At that rate, Omni is a creative exploration tool, not a production pipeline. Any internal use case that needs daily volume output — social content, localized product videos, support materials — won't fit inside current quotas.
No confirmed API. As of the I/O keynote, Google has not published official API endpoints, pricing tiers, rate limits, or developer documentation for Omni.5 The Developer Keynote on May 20 may change this. Until it does, no product commitment is possible.
The reasoning gap is still open. A new benchmark from Tsinghua University, WorldReasonBench, tested five commercial video systems — including Veo 3.1-Fast — across four reasoning dimensions: world knowledge, human-centered scenes, logical reasoning, and information reading.7 Commercial models scored roughly double open-source models overall, but logical reasoning was the hardest category for every model tested — the gap between "visually impressive" and "causally coherent" is still wide.
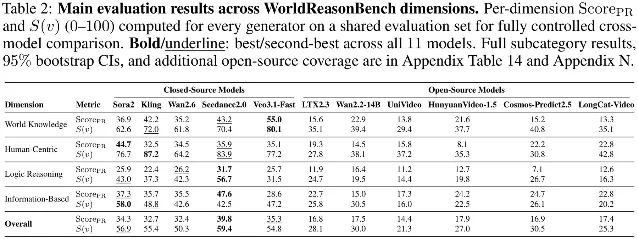
Image from: THE DECODER: New benchmark confirms AI video generators look stunning but still can't reason about the world
What to do with it
Here's a practical framework for three time horizons.
This week — set up the technical position:
- Monitor Google AI Studio (ai.google.dev) and the Google I/O Developer Keynote on May 20 for API announcements
- Get your team on the Vertex AI waitlist if you're already in the Google Cloud stack
- Run one internal pilot with a use case where the iteration cycle matters more than volume: a brand style test, an onboarding video prototype, or an internal science/technical explainer
Next quarter — design for the new interface paradigm:
Use cases where conversational editing produces disproportionate value:
| Use case | Why the quota cost is justified | Volume constraint |
|---|---|---|
| Brand/style A-B testing | One video per direction is enough to evaluate; fast iteration > high volume | Low |
| Educational/onboarding content | Long-form explainers take days to produce manually; Omni demo shows this is the primary use case Google optimized for | Low–medium |
| Product demo prototyping | Early-stage teams need quick visual prototypes to align stakeholders, not final assets | Low |
Conversely, social media scheduling, localized campaign rollouts, and support content all require daily output volume that current quotas cannot support.
Six-to-twelve months — watch the research signals:
The research this week points to where video models are heading next. Runway co-CEO Anastasis Germanidis explicitly stated the company's thesis: language models "are bound by our own understanding of reality," and training directly on world observational data is the path forward.8 The World Action Models (WAMs) survey paper (arXiv:2605.12090, May 12) formalizes this: the next generation of video systems won't just predict pixels — they'll model the joint distribution of future states and actions, targeting genuine physical reasoning.9
When that reasoning gap closes — which WorldReasonBench shows is still open — the use cases that become viable are not style transfer and brand testing. They're autonomous agents that can understand, plan, and verify actions in physical or simulated environments. That's the capability jump worth building a product roadmap around. It's not here yet. Watch for it.
TL;DR
- Gemini Omni (announced today at Google I/O) is a unified text + image + video model with conversational editing, available on AI Pro at $19.99/month
- The real shift: competitive advantage in AI video is moving from generation quality to editing workflow speed — the "Figma moment"
- Not yet: 2 videos ≈ 86% daily quota, no confirmed API, IP/rights for video remix unresolved — treat as a prototype-and-watch tool, not production infrastructure
Cover image from: CNET: Google I/O 2026 Live Updates
参考来源
- 1CNET: Google I/O 2026 Live Updates
- 29to5Google: Gemini 'Omni' video model shows up with early demos
- 3Tweet by @sergeonsamui
- 4Tweet by @luciano_rj: Gemini Omni pricing confirmation
- 5PixVerse: Gemini Omni Video Model Leak Review
- 6CNBC: Google I/O — Alphabet's AI showcase is its chance to wow Wall Street
- 7THE DECODER: New benchmark confirms AI video generators look stunning but still can't reason
- 8TechCrunch: Runway started by helping filmmakers. Now it wants to beat Google at AI.
- 9arXiv: World Action Models — The Next Frontier in Embodied AI
围绕这条内容继续补充观点或上下文。